WSDM 2018
摘要
Convolutional Neural Networks (CNNs) have been recently intro- duced in the domain of session-based next item recommendation. An ordered collection of past items the user has interacted with in a session (or sequence) are embedded into a 2-dimensional latent matrix, and treated as an image. The convolution and pooling opera- tions are then applied to the mapped item embeddings. In this paper, we first examine the typical session-based CNN recommender and show that both the generative model and network architecture are suboptimal when modeling long-range dependencies in the item sequence. To address the issues, we introduce a simple, but very effective generative model that is capable of learning high-level representation from both short- and long-range item dependencies. The network architecture of the proposed model is formed of a stack of holed convolutional layers, which can efficiently increase the receptive fields without relying on the pooling operation. Another contribution is the effective use of residual block structure in recom- mender systems, which can ease the optimization for much deeper networks. The proposed generative model attains state-of-the-art accuracy with less training time in the next item recommendation task. It accordingly can be used as a powerful recommendation baseline to beat in future, especially when there are long sequences of user feedback.
目前有挺多CNN结构被用于解决session based中的sequence问题
用户发生交互的item序列的embeddings,可以组合成2-D matrix treated as an image
目前基于CNN的模型在面对long-range item sequence效果都一般
提出一个可以从short- and long-range item dependencis提取high-level representation
结构:
- 层叠的空洞(stack of holed)卷积来扩大receptive fields
- residual block structure, 易于深度网络的优化
目前捕捉交互序列的模型主要分两类,RNNs 和CNNs,但是RNNs没办法充分的利用并行计算,在训练和评估的时候速度受限
而CNNs在计算时不依赖于之前的状态,因此可以充分并行
Caser [29], abandoned RNN structures, proposing instead a convolutional sequence embedding model, and demonstrated that this CNN-based recommender is able to achieve comparable or superior performance to the popular RNN model in the top-N sequential recommendation task.
t个item,每个item k维embedding,构成t x k embedding matrix
常见的CNNs模型使用max pooling操作,只保留最大值,来增加receptive field,并处解决变长sequence问题。
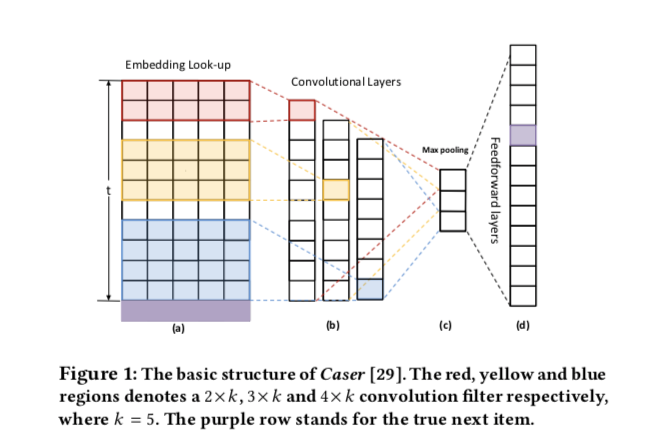
Caser的几个问题
- max pooling在cv领域里是安全可用的,但是在long-range sequence data里可能会丢失important posion and recurrent signals.
- generating the softmax distribution only for the desired item fails to effectively use the compete set of dependencies
当sequence越长,上述的问题越明显
为解决上述问题
- 直接估计output sequence 分布,而不是最想要的那个
- 不使用无效的huge fikers, stack 1D dilated conv layers,增大receptive fieldss model long-range dependencies,不使用pooling layer
- residual network解决深度网络优化问题
早期序列化推荐主要是马尔科夫链和矩阵分解,但是马尔科夫链不太能拟合序列数据的复杂关系。
For example, in Caser, the authors showed that markov chain approaches failed to model union-level sequential patterns and did not allow skip behaviors in the item sequences.
RNN目前几乎统治着sequential recommendation,GRURec -> various RNN variants -> adding personalization , content and contextual feature -> attention mechanism -> different ranking loss
Recently, deep learning models have shown state-of-the-art recommendation accuracy in contrast to conventional models. Moreover, RNNs, a class of deep neural networks, have almost dominated the area of sequential recommendations. For example, a Gated Recurrent Unit (GRURec) architecture with a ranking loss was proposed by [15] for session-based recommendation. In the follow-up papers, various RNN variants have been designed to extend the typical one for different application scenarios, such as by adding personalization [25], content [9] and contextual features [27], attention mechanism [7, 20] and different ranking loss functions [14]
MODEL DESIGN
- our probability estimator explicitly models the distribution transition of all individual items at once, rather than the final one, in the sequence;
- our network has a deep, rather than shallow, structure; ’
- our convolutional layers are based on the efficient 1D dilated convolution rather than standard 2D convolution; and
- pooling layers are removed.
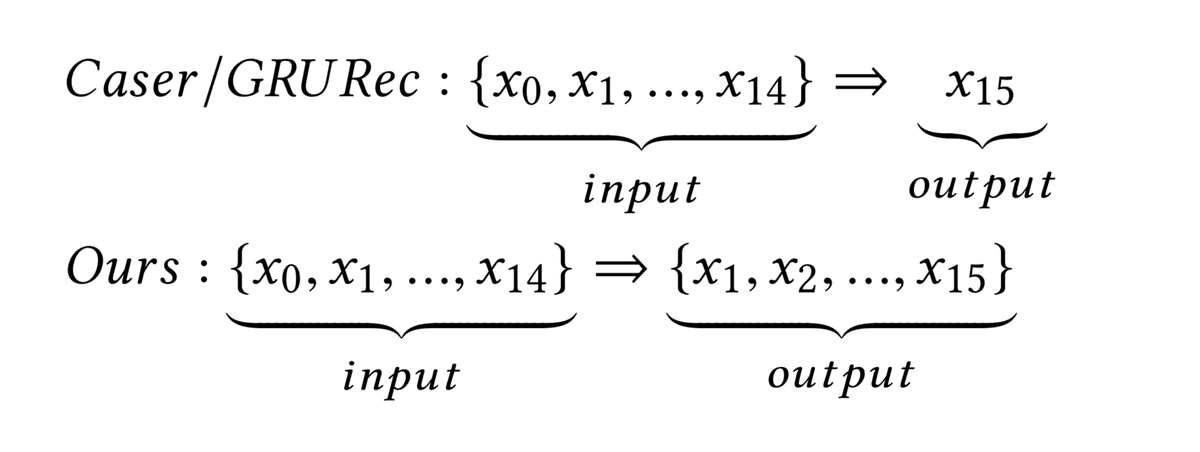
通常情况,会生成很多子序列数据来进行模型训练
作者认为优于是分别对子序列去各自优化,不能保证最优结果。而且会导致很多计算上的浪费。
后边的实验对此进行了比较
Network Architechture
input: length: t , embedding size: 2k
1D dialted CNNs
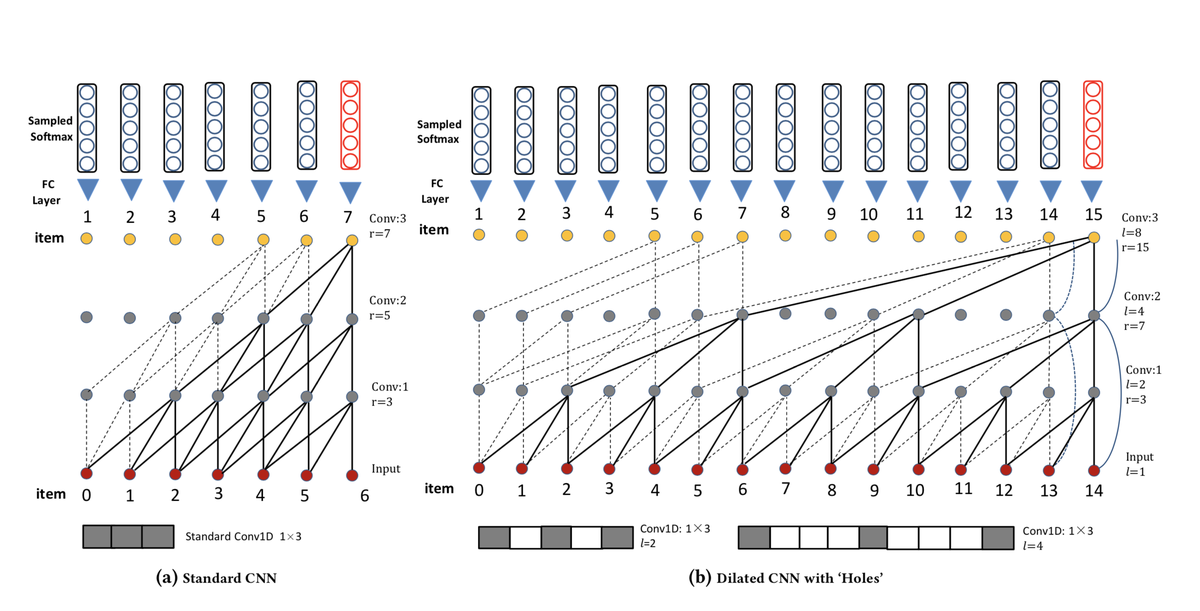
b图中,dilation factor 是 1,2,4,8
we denote receptive field, j-th convolutionallayer,channel and dilation as r, Fj, C and l respectively.
当卷积核宽度为3时,dilated convolutions的感知区域为 r = 2**(j+1) - 1,而普通卷积的r = 2j + 1Formally, with dilation l, the filter window from location i is given as
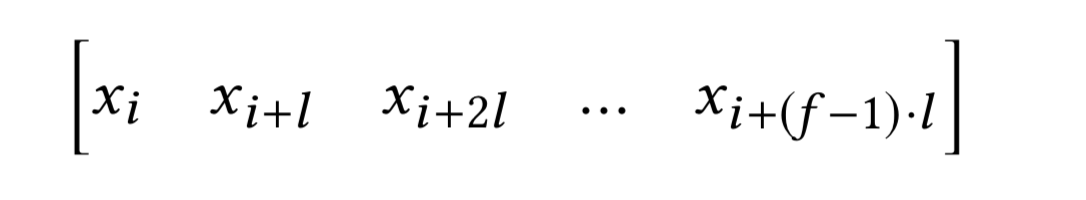
the 1D dilated convolution operator ∗l on element h of the item sequence is given below, where g is the filter function.
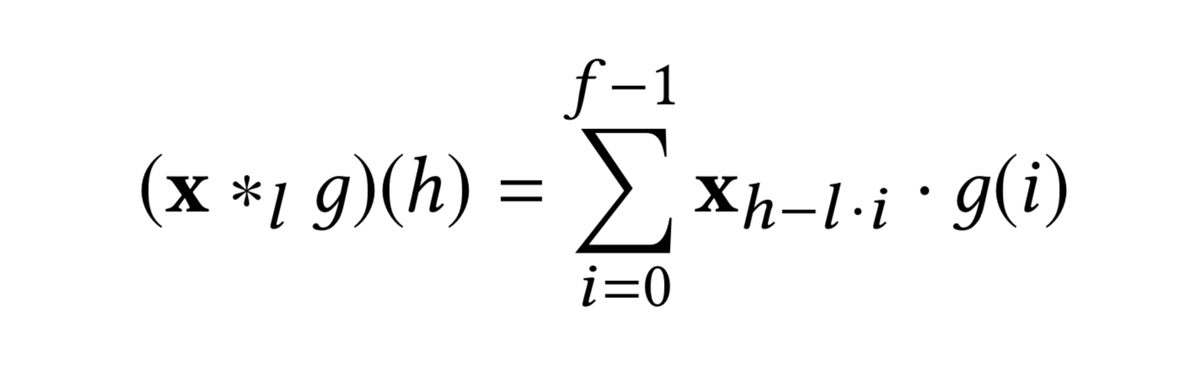
显然,dilated convolutional structure 更高效的解决了长序列,无需大的卷积核和更深的网络。
实际上,增加模型的容量和感知范围,只需重复的1,2,4,8,1,2,4,8这样的摞就可以了。
与其他模型将t X 2k 理解为2Dmatrix不同,这里把它理解为1 X t X 2k, 2k被看做图片的channel而非,卷积核的宽度。
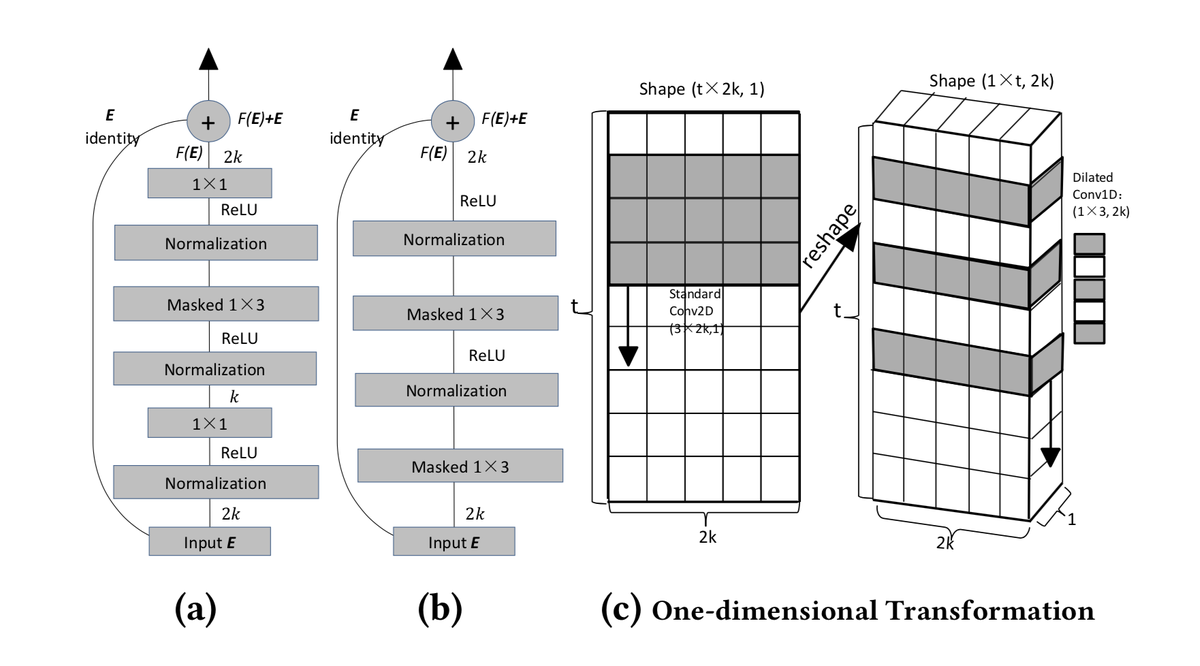
H(x) = F(x) - x
(a)中使用1x1的卷积将维度从2k缩到k,再用1x1卷积将其回复为2k,这样可以减少参数的数量
(a)的参数1 x 1 x 2 k x k + 1 x 3 x k x k + 1 x 1 x k x 2k = 7k**2
(b)的参数 1 x 3 x 2k x 2k = 12k**2

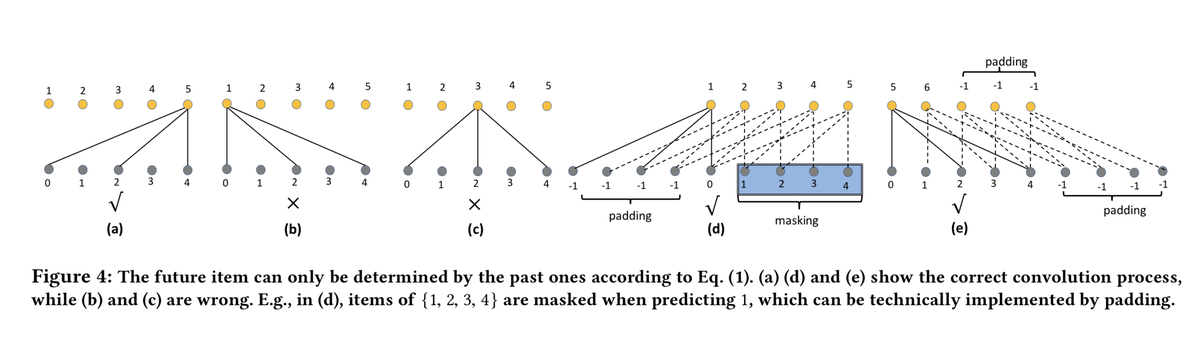
Dropout-mask
避免信息泄露,需要对结构做调整,不能让未来的item信息来预测当前item
Final Layer, Network Training and Generating
优化目标是最大化log-likelihood, 最大化logP 等价于最小化binary cross-entroy loss的和
softmax开销太大,用smapled softmax和负采样解决
EXPERIMENTS
- YOO数据集:因为96%的长度小于10,所以直接移除大于10的4%,作为short-range seq data
- MUSIC数据集: 大部分人每周听歌上百次,可以作为long-range seq data
这两个数据集的效果可以表现出模型在short-range和long-range上的效果
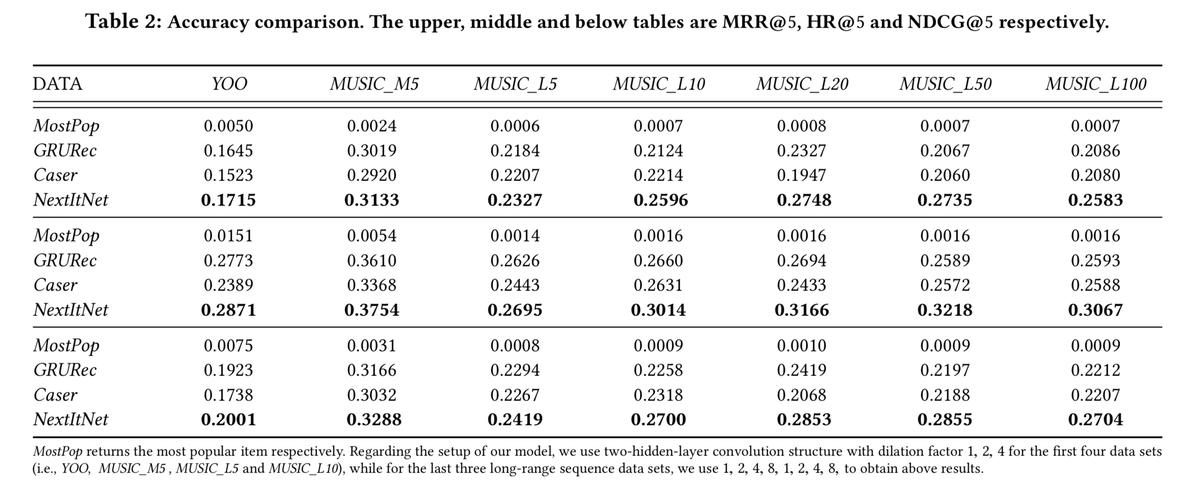
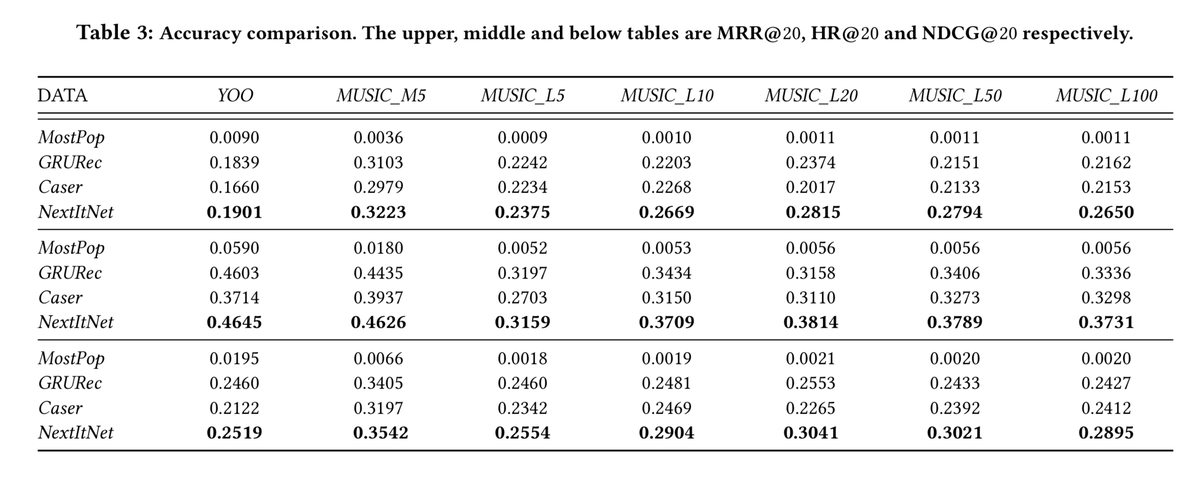
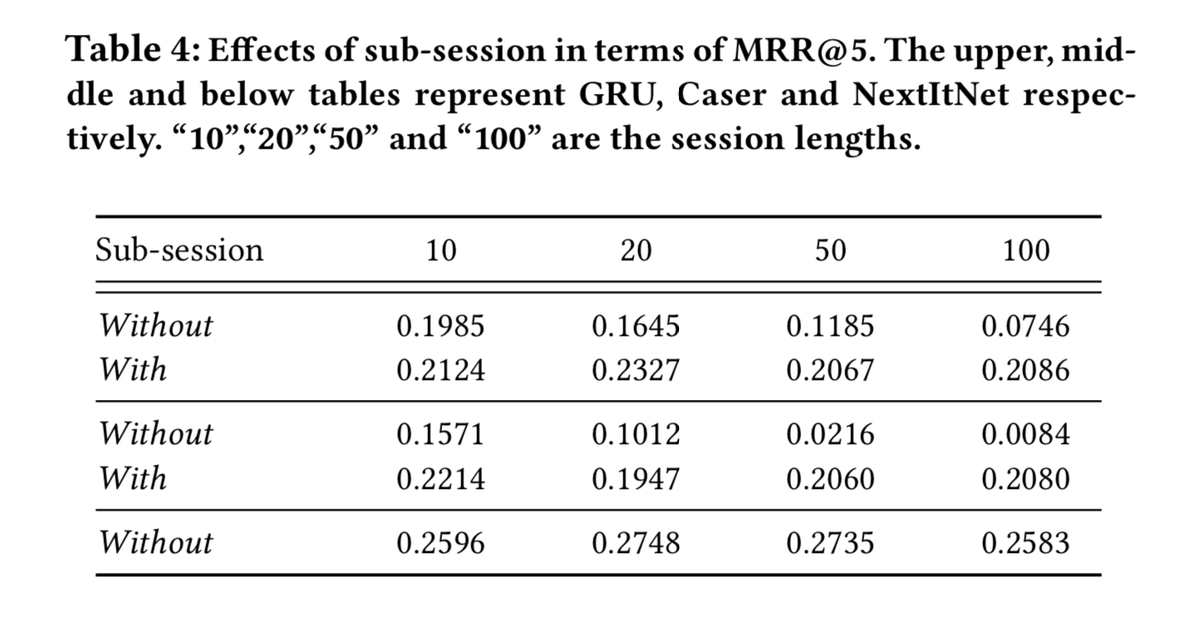

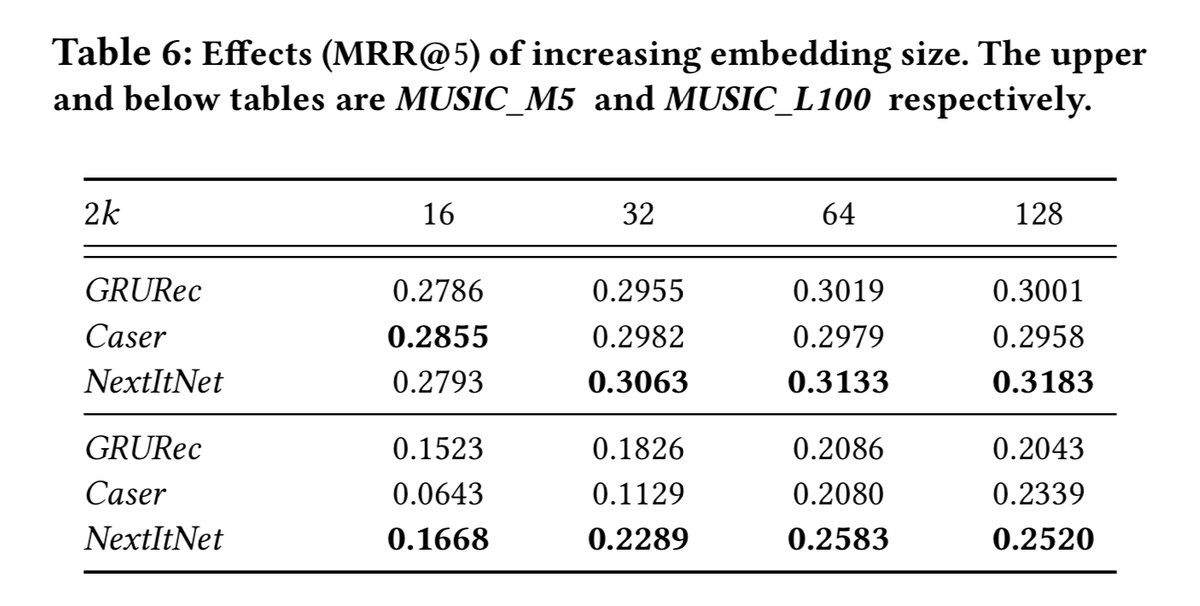
小数据集上的效果
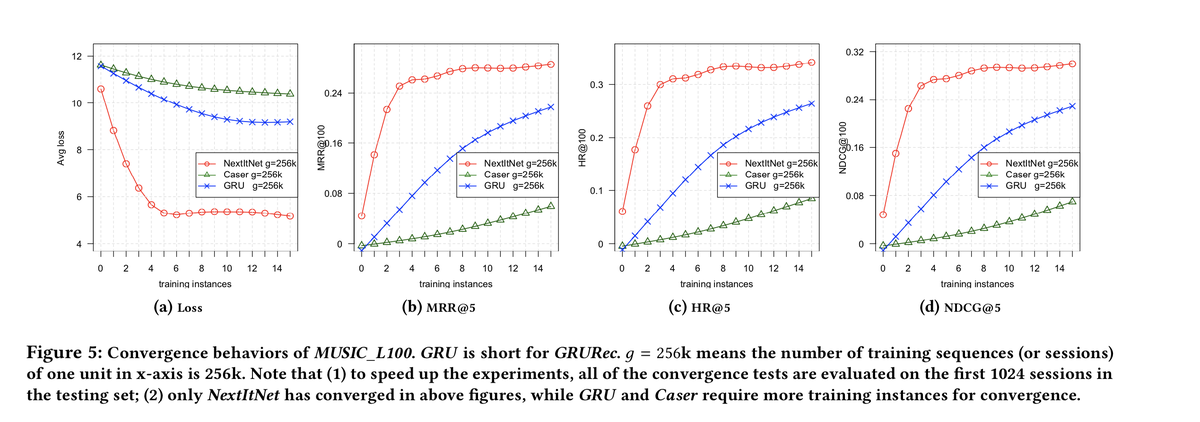
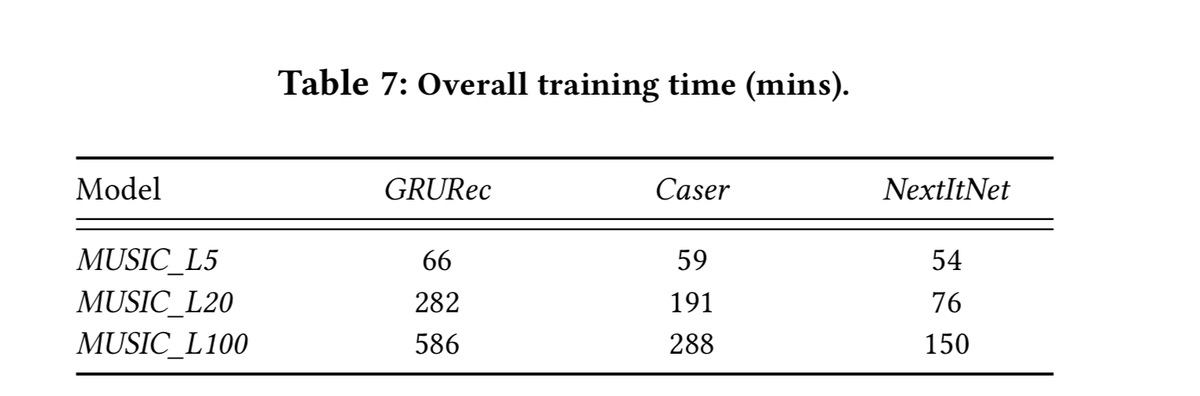
总结,准确率高,并行度高,训练速度快,相同数目的样本收敛快