最近因为业务量上涨,系统压力比较大,需要对部分逻辑进行解耦,于是想引入个消息系统来搞下
最近因为业务量上涨,系统压力比较大,需要对部分逻辑进行解耦,于是想引入个消息系统来搞下。
选择nsq,一是因为别人推荐,二也是语言方面,之前搞过段时间go,觉得上手会比较快,下面简单记录了nsq的一些特点
NSQ 分布式消息系统
特点
- 支持分布式拓扑,避免单点故障(SPOF)
- 水平扩展
- 消息延时低
- 支持负载均衡以及多播消息路由
- excel at both streaming (high-throughput) and job oriented (low-throughput) workloads
- 队列在内存中(也支持写入硬盘)
- 实时为消费者发现生产者
- TLS
- 数据格式多样
- 依赖少(易部署)
- 简单的TCP protocol,支持各种语言的client
- HTTP interface for stats, admin actions, and producers
- 嵌入statsd
- 健壮的集群管理界面(nsqadmin)
保障
消息高可用
系统支持 —mem-queue-size选项,即队列中超过—mem-queue-size的消息内容将会被写入disk中。—mem-queue-size可以被设置为0,即所有消息都写入disk
消息没有内置重复,不过有很多权衡方法,比如拓扑、以容错方式主动从属以及将消息保存在磁盘中消息可以多次传递
在nsqd节点不挂的情况下,当客户端timeouts, disconnections, requeues时,消息可以被系统再次传递消息无序
集群消息无序,不过单nsqd上的消息是有序的。因为nsqd之间无共享consumers eventually find all topic producers
依托nsqlookupd,nsqd会与nsqlookupd保持连接
nsq的生产与消费
目前的分布式消息系统的逻辑在许多方面都是共通的
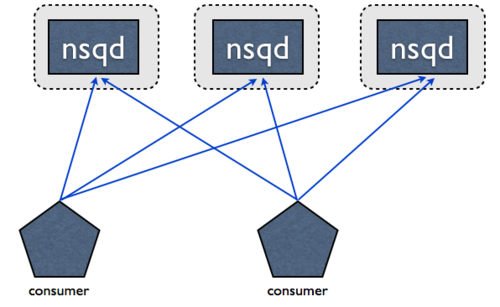
Producer生产数据,生产的同时让系统对应产生了一个topic。
一个topic下可以对应多个channel,这些channel的数据是都是一样的,复制与topic中。Consumer消费的是channel中的数据,多个Consumer可以消费一个channel,多个consumer消费的数据总和对应的是channel中的数据。
如下图:

无单点故障(SPOF)
NSQ在设计初始便是分布式的,NSQ客户端通过TCP连接着所有提供指定topic的nsqd。NSQ没有中间存储,没有消息代理,没有单点故障。
消息传递保证
nsq保证消息可被以多次传递,尽管可能会有重复消息。Consumers应该期望这一点,并删除重复数据或执行幂等操作。
此项被强制作为协议的一部分执行,并按如下方式工作(假设客户端已成功连接并订阅主题):
- 客户端通知nsqd他们已经准备好接收消息
- NSQ发送消息并在本地临时存储数据(在re-queue或timeout的情况下)
- 客户端回复FIN(finsh)或者REQ(re-queue)表明成功或失败。如果客户端在一定时间内没有回复NSQ,则timeout,NSQ将消息re-queue
这确保了只有当nsqd进程被不正常关闭时,才会引发消息丢失这一唯一的边缘情况。
预防消息丢失是极其重要的事情,甚至在边界情况下我们也要保证消息不丢。一个解决方案是容忍消息冗余,在不同的host上存储同样的消息备份。因为consumer应该是幂等的,所以一份消息消费两次并没有什么影响(除了性能),这保证你的系统中一个节点故障后仍然不会丢失消息。
另外,NSQ提供了一些模块来支持各种生产用例和可配置的持久性。
内存占用控制
nsqd提供了一个可配置的选项—mem-queue-size,它决定了给定queue可以在内存中存储的消息数。如果消息数超过之前设定的阈值,消息就会被写入disk中,通过—mem-queue-size参数的设置限制了nsqd进程的内存占用
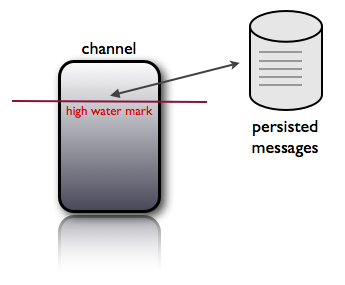
聪明的观察者可以发现通过将—mem-queue-size设置为1甚至是0,可以非常方便的去保证消息传递的可靠。disk-backed queue保证了系统有效规避异常重启
同样,如果想关机的话,可以通过信号,让nsqd将内存里和正在传递的信息存储在硬盘中。
注意,其名称以字符串#ephemeral结尾的topic/channel不会缓存到磁盘,而是会在传递mem队列大小后丢弃消息。
高效
NSQ被设计为通过“memcached-like”有大小前缀的命令协议进行通信。 所有消息数据保存在core中,包括诸如尝试次数,时间戳等元数据。这避免了在服务器到客户端之间来回复制数据,这是先前工具链在重新排队消息时的固有属性。 这也简化了客户端,他们不再需要维护消息状态。
针对数据协议,我们做出了一个关键的设计决策,就是主动将数据推送到客户端而非等待它来拉取,来最大化性能和吞吐量。 这个概念,我们称为RDY状态,本质上是一种形式的客户端流控制。
当客户端连接到nsqd并订阅一个channel时,它被置于RDY状态0。这意味着没有消息将被发送到客户端。 当客户端准备好接收消息时,它发送一个命令,将其RDY状态更新为某个它准备处理消息数目,例如100。无需任何附加命令,100个消息将被推送到客户端,如果它们可用(每次递减该客户端连接的服务器端的RDY计数)。
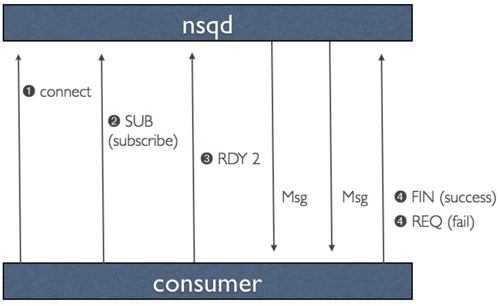
这是一个显着的性能调节,因为一些下游系统能够更容易地进行批处理消息并且从一个更大的max-in-flight中显著获益。
显然,因为它要有缓冲和推送的能力,以满足对不同流(chennel)有独立副本的需要,我们生成了一个守护进程,其行为像simplequeue和pubsub组合。 我们的系统将传统的保留上面讨论的工具链,这在简化我们系统的拓扑结构方面是强有力的。